The idea
Recently, some of my friends decided to hold an online tournament, and the main tournament organizer wanted everyone to be able to stream their screens so the production crew could grab live feeds and multiplex/composite them, ultimately feeding an "official" production tournament broadcast to a streaming service like Twitch.
Originally, they were planning to use a service like VDO.Ninja for everyone to stream to. VDO.Ninja has inbuilt compositing capabilities, allowing someone to select an individual stream and show it, show two streams side-by-side, etc. Not only that, but contestants wouldn't have to set up any streaming software since VDO.Ninja uses WebRTC on the browser for streaming, making streaming really easy for contestants with less technical skills.
Problems
The only thing VDO.Ninja lacked was recording capabilities. Part of the reason is that WebRTC is fundamentally P2P, meaning streams aren't first delivered to a central server, where they can be saved, before delivering to clients. While there was some tooling to export VDO.Ninja broadcasts into another server (built by a VDO.Ninja maintainer, I think), I found it kind of finnicky to work with. We really wanted every stream to be recorded though since we might miss important highlights live, and we want the ability to dig through individual streams to compile a tournament highlights video after.
I happened to have recently watched an old video by Nerd on the Street where he set up a simple HLS streaming server with NGINX, powered by an RTMP module written for NGINX. Setting it up locally was extremely simple, taking me only 15 minutes or so to get a POC up. I got an NGINX instance compiled with arut's NGINX RTMP module running and I used OBS to send an RTMP stream locally and used OBS again to pull the RTMP stream. This demonstrated that we could pretty easily use an RTMP server for clients to send their streams to and then use OBS to pull streams from the RTMP server and use OBS to multiplex and composite the streams.
Digging it into the documentation for the RTMP module more, I found that it supported directives for recording. Awesome! This looks like exactly what we needed.
Emboldened, I started writing some configuration to deploy the RTMP server on a cloud service. I ended up chose AWS because it had servers fairly close to me, and I wanted to minimize latency as much as possible. I wrote some basic Terraform configuration for server provisioning, and an Ansible playbook to install Docker and deploy a compose file for an NGINX + RTMP image, alongside the NGINX configuration I needed.
We deployed the server on a tiny 1vcpu 1GB server and I was able to send a stream for a friend to pull. However, while I was waiting for packages to install on the low-powered server, I realized there might be a problem. We were going to have up to 40 contestants participating in the tournament. Granted, it wasn't certain that everyone was going to stream, but I wanted to prepare for the worst. If all 40 contestants streamed to the server, would a single server be able to handle it? Just forwarding a stream shouldn't be too intensive, but recording 40 streams at once sounded like it might be a problem. While we may be able to get away with one really powerful server for just 40 streams, I wanted a solution that could scale as much as needed.
My first move was deploying a Docker swarm, which allowed horizontal scaling really easily. I rewrote the Terraform and Ansible configuration to create a Docker swarm with an arbitrary amount of worker nodes and converted the compose file for the RTMP server into a stack with variable number of replicas. I deployed the infrastructure, sent some streams, and verified the load was being spread properly. However, I was only able to pull some of the streams. What was happening was that the streams I send (e.g. to /stream-1, /stream-2, ... were being load balanced on L4 by Docker's mesh network to some arbitrary RTMP container (as expected), but when I try to pull a stream, they might not be load balanced to the same container. Obviously, Docker's L4 load balancing isn't aware of the L7 stream paths. For some reason, I completely neglected to think about this. I'm too spoiled by HTTP, with its powerful L7 reverse-proxy ecosystem, I guess.
Infrastructure design
Taking a step back, I did some more research on the NGINX RTMP module and found some useful directives. The push and pull directives gave the server powerful relaying capabilities, allowing me to easily compartmentalize and topologize the infrastructure as desired. I still wanted to go with Docker Swarm instead of Kubernetes because Kubernetes seemed overkill and honestly, I was rusty on my Kubernetes. It had been over half a year since I administrated my last cluster. Additionally, I wanted to play around with Docker Swarm a bit more since it seems like a good middle-ground between a single node VM serving Docker containers and an entire Kubernetes cluster.
After some careful planning, I came up with this infrastructure:
- N ingestion nodes:
- Clients publish to these nodes.
- These nodes forward streams to recording nodes and a playback node.
- M recording nodes:
- Receives streams from ingestion nodes.
- Records streams and uploads them to an S3 bucket.
- 1 playback node:
- Receives streams from nodes.
- Serves streams to production crew for compositing.
Here's a diagram of the infrastructure:
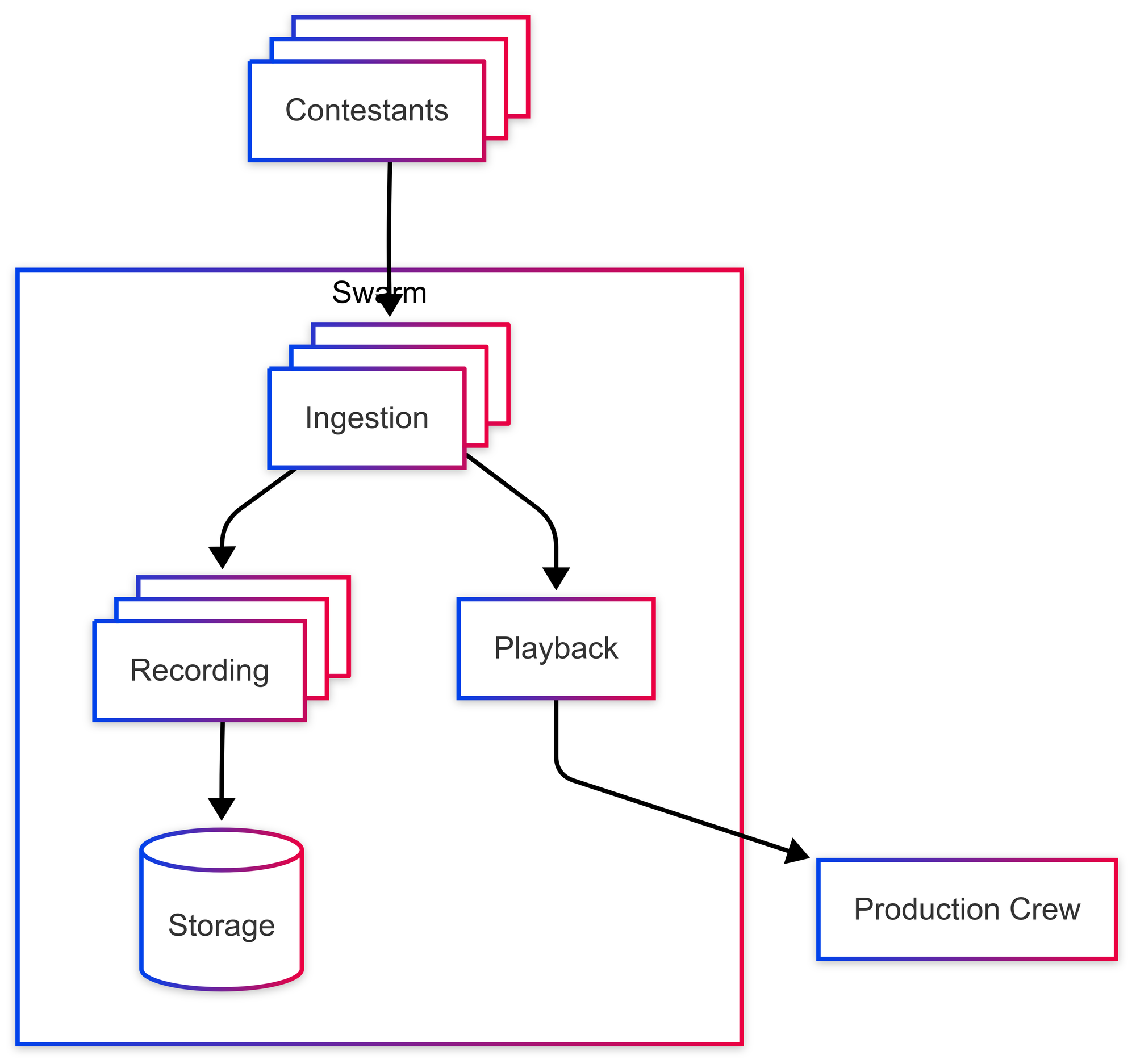
You might be wondering why there's only one playback node. As mentioned earlier, we need a L7 reverse proxy to load balance between playback nodes. While we could actually write a L7 reverse proxy by writing a small HTTP server that's called using the RTMP module's on_* directives alongside Docker Swarm's service discovery to poll internal nodes for whether they have a stream, I decided that would be overkill for this project. A single somewhat powerful playback node should be able to handle only forwarding streams for our purposes.
However, since I did mention scalable infrastructure in the title and I want to stay true to my word, I'll go into a bit more depth on how this would be done.
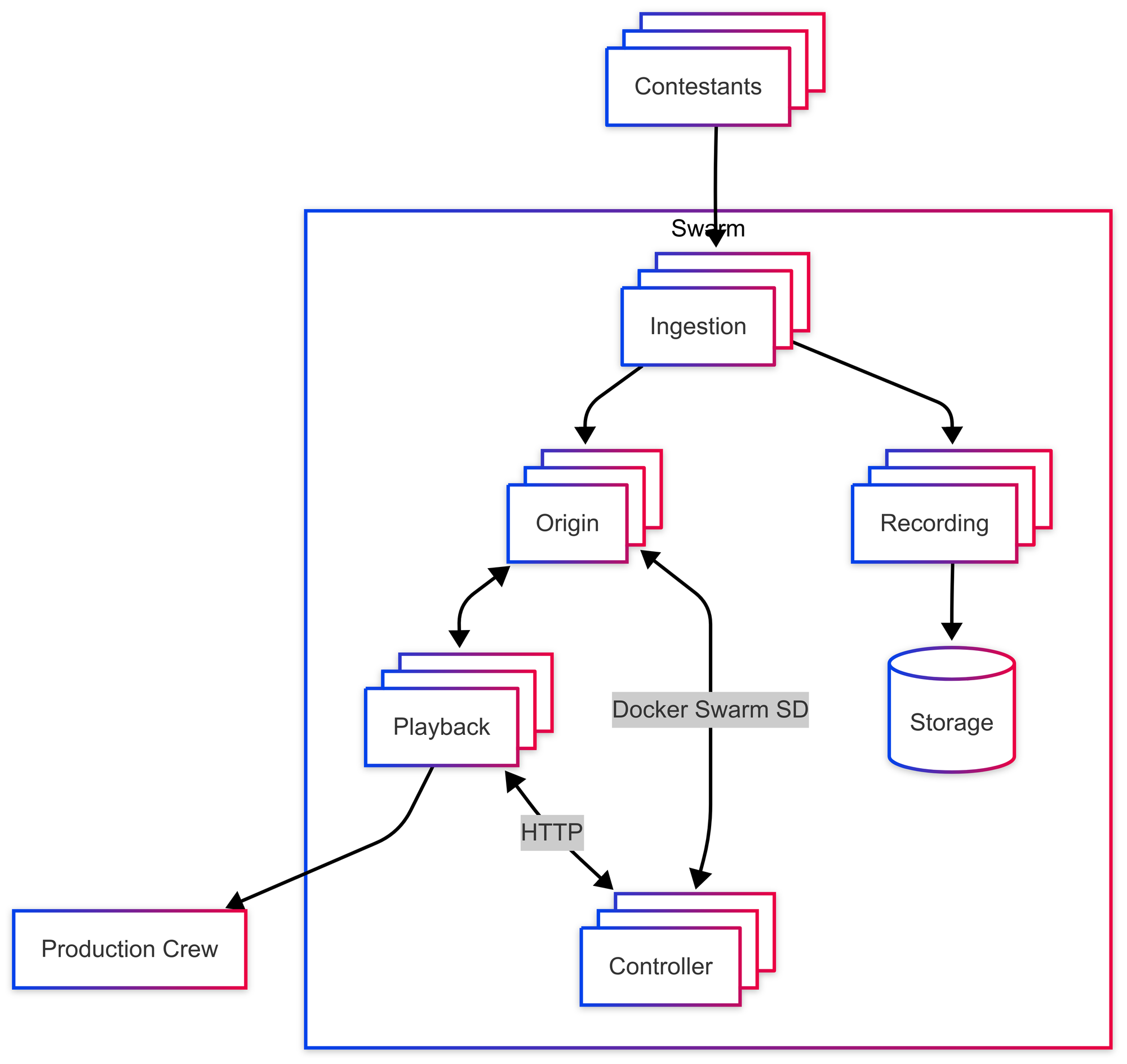
Let's break the changes down:
- We added a set of origin nodes to the cluster, which arbitrarily receives streams from ingestion nodes (the term origin is inspired from SRS, but another appropriate name might simply be relay) and simply wait to for the streams to be pulled.
- When a playback node receives a request for a stream, say
/stream-kfrom the production crew, we use theon_playdirective to make an HTTP request to a controller node requesting for/stream-k. - When a controller receives an HTTP request from the playback node, it uses Docker Swarm's service discovery (SD) to enumerate all origin nodes and poll each for whether
/stream-kis available on them and responds with an HTTP redirect to the origin node with/stream-kavailable. - When the playback server receives a redirect from a controller, it will start pulling from the origin node with
/stream-kavailable and send it to the requester.
With these changes, every component of the architecture can be horizontally scaled arbitrarily.
Anyway, I didn't do that because it was too high effort 😛. Instead, I added some authentication to the ingestion servers by using the on_play directive and writing a simple HTTP server that authenticated the stream path (what contestants would enter as the stream key on OBS) against a Redis database that mapped their stream key to a human-friendly path. For example, if I (Tony) streamed to the path/333fe3cc19f4a6c80cefb146a28883eb, I'd have a mapping from 333fe3cc19f4a6c80cefb146a28883eb to tony on the Redis database, which would make the ingestion node relay the stream to playback and recording nodes on the path /tony. This made naming recordings easier as well as give the production crew human-friendly stream paths to pull from.
Additionally, I added some monitor tooling with Grafana, Prometheus, cadvisor, node-exporter as well as a Redis admin panel to mess around with stream keys on-the-fly and Traefik as an HTTP reverse proxy for basic authentication. I also wrote a small web application that connected to a mod for the we were playing to expose an admin interface on the browser as well as gave live updates to the web application, but I won't go into detail for that in this post.
The remainder of this post is about how the tournament turned out and my stories from it. If you're only interested in streaming architecture, there's no discussion of that beyond this point.
Pilot
We set a date to host a mini-tournament with a quarter of the contestants to test out the streaming infrastructure. I ran a few commands to set up the swarm, we distributed streaming keys, and it worked like a charm. I monitored the server loads on my Grafana dashboard and they were holding up amazingly with 10 concurrent streams. None of the servers were even hitting 50% load per CPU. I was feeling confident we'd be able to handle 4x the load as long as I scaled accordingly. After destroying the swarm, all there was left to do was wait for the day of the tournament.
But of course I didn't do that. I knew there were some improvements to be made. Namely, the playback server didn't have any authentication mechanism, meaning malicious actors could potentially publish and override a contestant's stream. Obviously, no one was going to do that, but I had the programmer's itch to achieve perfection, against my best judgement.
So, after making sure to freeze the configuration that worked during the mini-tournament in Git, I started hacking at a solution. Part of what made it nontrivial was that through Docker's ingress network, an SNAT is applied that masquerades the original client IP, making it difficult to deny publishing using IP ranges. Without going into too much detail, I found a solution that seemed to work. After some more testing, I was happy with what I had and settled with this version for the tournament.
Mayday
T-2h
The day of the tournament finally arrived. Two hours before the start of the tournament, I spun up the streaming infrastructure and the production crew started setting up their software. A few contestants arrived early and started streaming to the server. Some streams weren't showing up on the production crew's feed, but I gave it little thought because I knew it could take a while to connect and sometimes you just have to refresh the streams.
T-1h
There was one contestant who said he had been streaming to the server the entire time it was up, yet the production feed wasn't picking up on it. Strange. I started deeper investigation by trying to pull feeds from all the contestants that were streaming. Some of them weren't showing up. At this point, I was starting to get anxious, wondering if I should roll back to the version that worked during the pilot run or whether I could diagnose the problem before the stream started.
T-45m
More and more contestants were showing up and starting to stream now. Some streams still were not showing up and I hadn't found a diagnosis, much less a solution. Spinning up the entire infrastructure took about 15 minutes. There was no time left and the situation was getting dire. I decided to allot 15 minutes to finding and fixing the issue, otherwise it was time to roll back. I muted and deafened myself, blocking out the noise from the growing number of contestants joining the call and focused all my attention on making sure things worked. There were 40 contestants and a handful of production crew, all of who were depending on the streaming infrastructure. I had to do whatever I could to get it running.
T-30m
15 minutes of furiously issuing commands still left my empty-handed. There was no other choice than to roll things back. I sent a message to a tournament organizer telling them to notify the dozen or so contestants streaming that the server would be going down temporarily. I destroyed the infrastructure and reverted the configuration to the stable version. I ran the commands to spin up the new infrastructure and waited in apprehension, watching each command fly by. What if even rolling back doesn't work? I wondered. I shook the thought off. It will work. I reassured myself.
T-15m
The streaming server was back up. I began receiving notifications that some contestants started publishing to the server, while others waited for DNS records to propagate. I checked in with production. We were receiving feeds for all publishing contestants. I breathed a big sigh of relief. It seems like at least this problem was solved. But there were more problems to come.
T-5m
There were still a few contestants unable to connect to the server, and I was sent to diagnose the issue. After going through all the standard procedures like making sure the URL was used, the right stream key was inputted, etc., they still weren't able to connect. It couldn't be a DNS issue, could it? I mean, I set a TTL of 600s on the records, the lowest my registrar allows, and it's been well over 600s. I thought to myself. To make sure, I guided a contestant to do an nslookup on my domain. She was still hitting the cache for the old records, and I assume this was the case for the other few contestants that were experiencing similar issues. Frantically, I searched up how to flush the DNS cache on Windows and relayed the information to them. No luck. Maybe the records were still cached externally. My last resort was to ask them to edit their hosts file, which is seriously a pain on Windows. Yet it still didn't work!
At this point, I should have asked them to stream to the IP address directly. RTMP servers don't do any hostname identification, after all. However, I was too caught up in the chaotic atmosphere, so focused on making sure the domain resolved correctly as the solution that I didn't think of this. Out of ideas, I could only apologize to the contestants and ask them to try again in a few minutes.
T+10m
We were past the planned start time, but between contestants showing up late, tournament organizers having their hands full dealing with questions from the contestants and a general lack of preparation, we were running late on schedule. Fortunately, I had a chance to breathe because the technical issues seemed to have been resolved. I check up on my Grafana dashboards I had prepared to see how the server was holding up. 400% system load per CPU on one of the servers was the first thing I saw. My face went white. We were 15 minutes past the start time. Scaling horizontally doesn't solve the issue because it seemed to be just the playback container generating this load. The only way to handle this load was scaling vertically, which meant destroying the infrastructure and rebuilding it again.
My mind was racing. The importance of making the correct decision fast was not lost upon me. I didn't have time to think about why there was so much load compared to the test run. I thought hard about what I should do for a minute. If we continue under this extreme load, there could be problems with playback, causing problems with the broadcast. Since I also didn't distribute the placement of the containers well, there seemed to also be a recording container scheduled on the server with high load, meaning there could be recording issues too. However, If I vertically scale, this would cause the infrastructure to be rebuilt, causing everyone to disconnect and possibly never reconnect, given the DNS issues we had earlier.
I made the hard decision to vertically scale. My plan was to scale up first, and then start re-balancing the containers after. There was no chance I could re-balance the containers with the current infrastructure, with just one container being under so much pressure. I also didn't configure a re-balance before I spun up the new infrastructure because I needed to get the new infrastructure up ASAP. So I destroyed the infrastructure and started rebuilding it with higher spec'd VMs. I didn't notify anyone of this decision since there was so little time to lose and contestants were left wondering why they disconnected.
T+20m
After a painful 10 minutes, the servers were up and contestants were connecting back to them. However, there was one server that just failed to start and the command to deploy the Docker stack was hanging, even though contestants were connecting. In retrospect, my guess is that all the contestants and the production crew constantly trying to connect to the servers at once affected the startup, causing it to behave strangely. As for why one server failed to start, I still have no idea. I guess I got unlucky.
Even though almost all of the contestants connected back, I was still anxious. Looking at the dashboard, I saw that the server load per CPU was still around 220%. More importantly, the command to deploy the stack was still hanging. The second part of my plan to re-balance the containers after the initial deployment hadn't been executed yet, and this was vital for further reducing the load. The only thing I could do as I waited for the command to finish was read Docker documentation to see what else I could tune.
T+25m
The command still hadn't terminated. Even though the stream seemed to be going smoothly, I knew I had to apply the configuration to re-balance the containers. The tournament had officially started now and the production crew was broadcasting to Twitch. I held my breath as I CTRL+C'd out of the hanging command, waiting to see if any streams died.
After a minute of waiting, nothing happened. The streams were continuing like normal. Alright, there's just one last step of this plan. I thought. I just have to apply this configuration that should help re-balance the containers.
I ssh into the manager node and carefully edit the compose file, making sure not to make any changes to the playback container. I was fine with ingestion and recording containers being rescheduled, since a new replica should take its place before the old one shuts down, meaning there would only be a brief interruption, but the playback container could not be touched since there could only be one of them.
T+30m
After double-checking and triple-checking the configuration, I run a docker stack deploy. The playback container goes down. The production crew's streaming software crashes from this interruption, and a fallback broadcast is sent to Twitch. I still don't really get why the playback container went down. Normally, if you don't make any changes to a service's configuration and re-deploy the stack, nothing happens to it. I think it must be because the service didn't start up properly earlier, as indicated by the command hanging.
In any case, we were on code red. One of the casters had to take over and make some small talk during this downtime, and I couldn't do anything other than wait for the stack to come up.
After an agonizing few minutes, it fortunately did. We re-launched the crashed software and the streams came back online one-by-one. We redirected the broadcast to the contestant's screens and things were back to normal.
One of the servers was still under fairly heavy load (around 150% system load per CPU, spiking occasionally to 180%). Additionally, one of the containers still didn't seem to be rescheduled correctly (likely a misconfiguration on my end), but seeing that the streams were running smoothly after a few minutes, I relaxed. Plus, I was way too scared of making any changes, even if they should be safe, given how catastrophic it was earlier.
T>30m
After a turbulent start, the rest of the stream went relatively according to plan. People seemed to have fun and the tournament turned out pretty well. Well, except for the fact that we never actually recorded the main broadcast. We had made a new Twitch account for this and forgot to enable recording broadcasts. So while we recorded the contestant's individual streams, we didn't have the main broadcast, which included at least the commentary of the casters, the stream chat, and the general atmosphere of the stream. 🤦
Reflections
So, what went wrong that day?
To start, I shouldn't have deployed the unstable configuration. Even though I thought I tested it well and even though I still don't know why it didn't work, I can't really justify "securing" the playback servers against unauthorized publishing by using the unstable configuration. This didn't end up being that big of a factor though. After all, I did have my backup plan of reverting to the stable version, which was executed almost perfectly. The only thing I didn't account for was DNS taking too long to propagate, which did end up causing some issues.
Really, the biggest factors were poor container balancing and the single playback container being a bigger bottleneck than I thought. While it's somewhat unreasonable to redesign the architecture to handle multiple playback containers as suggested above, I totally could've vertically scaled the node handling playback to have much higher specs as well as done a better job making sure no other containers were scheduled on the playback node.
Even with a few hiccups here and there, this was a great experience. I learned about streaming architecture, tournament planning, and it was great to see everything come together. In preparation for the next tournament, I've ported the architecture to use MediaMTX containers, which has richer features than just an NGINX-RTMP container.
Check out the repository on the stable commit if you'd like.
The MediaMTX port is still a WIP as the next tournament date is still in limbo, but you can check out my current version here.
How I set up scalable, high capacity streaming infrastructure
My story setting up a scalable, high-capacity streaming server for a tournament and mistakes I made.